IT Best Practices: Integrating Data Warehouses with Data Virtualization for BI Agility
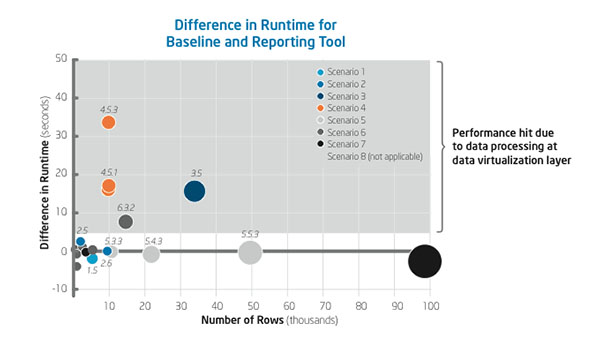
IT Best Practices: By deploying data virtualization solutions that combine disparate data sources into a single virtual layer, Intel IT expects to increase the agility of our business intelligence (BI). This agility will enable our business groups to more quickly solve business problems, discover operational efficiencies, and improve business results worldwide. Our tests show that data virtualization solutions deploy quickly and provide a performance boost when some initial processing is pushed down to source containers. As Intel IT transitions from a “one size fits all” enterprise data warehouse (EDW) to a multicontainer approach, we need new fast, cost-effective ways to access and process the data in these containers. Such tools will enable Intel IT to help our IT customers more effectively integrate data from our big data solutions, custom independent data warehouses, and traditional enterprise data warehouses. We tested the data virtualization capabilities of two commonly used enterprise software products: an extract-transform-load (ETL) tool and a reporting tool. Using data from Intel’s customer insight program, we employed these solutions on data in multiple containers and compared their performance against a baseline data virtualization setup drawing data co-located in a single source. We made the following discoveries:
• The data virtualization solutions required just one week to set up compared to approximately eight weeks for a traditional co-location approach that copies all data sets to a single container.
• Optimizations that push filtering down to the source container resulted in the best performance.
• The more processing that can be pushed down to the source container, the higher the performance. Results from these tests are guiding our deployment of data virtualization to increase our BI agility. We are also investigating more robust, dedicated data virtualization tools.
For more information on Intel IT Best Practices, please visit intel.com/IT
Posted in:
data centers, Information Technology, Intel, Intel IT, IT White Papers, IT@Intel
















