Evaluating Apache Hadoop Software for Big Data ETL Functions
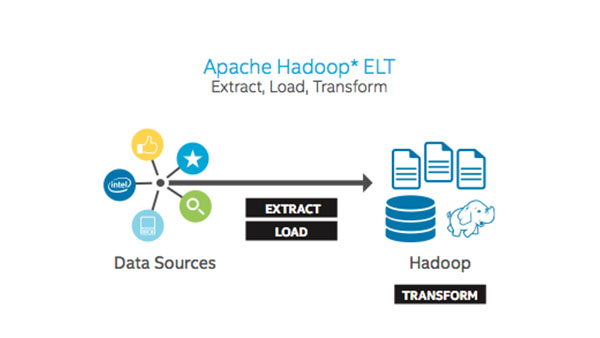
IT Best Practices: Intel IT recently evaluated Apache Hadoop software for ETL (extract, transform, and load) functions. We first studied industry sources to learn the advantages and disadvantages of using Hadoop for big data ETL functions. We then tested what we learned with a real business use case that involved analyzing system logs as well as a cost comparison of Hadoop and our third-party ETL tool.
We determined that using Hadoop for ETL functions works well for datasets that are coming from, passing through, or resting in Hadoop. Specifically, Hadoop makes sense for simple extract and load operations performed on those datasets.
For more information on Intel IT Best Practices, please visit intel.com/IT
Posted in:
Big Data, Information Technology, Intel, Intel IT, IT White Papers, IT@Intel
















